 1 Speech Recognition Algorithm At present, speech recognition in consumer electronic products is often implemented by a single-chip computer (MCU) or DSP as an inflammatory hardware platform. This kind of speech recognition is mainly isolated word recognition. It has two implementation schemes: one is based on the hidden Markov statistical model (HMM) framework for non-specific person recognition; the other is based on the dynamic programming (DP) principle. Specific person identification. They have advantages and disadvantages in their applications. The advantage of HMM non-specific personnel is that the user can be used directly without training; and has good stability (that is, the speech recognition performance does not decrease with time for the user). However, non-specific speech recognition also has its drawbacks that are difficult to overcome. First of all, using this method requires a large amount of corpus to be collected in advance in order to train the corresponding recognition model, which greatly increases the upfront cost of applying this technology. Secondly, non-specific person speech recognition is difficult to solve the problem of different dialects in Chinese, limiting Its use area; another factor should also be considered, the specific command words used for control in home appliances should not be completely fixed, and should be changed according to the user's habits, which is hardly recognized by non-specific people. Possible to achieve. Therefore, most home appliance remote controls are not suitable for this solution. The advantage of DP specific person identification is that the method is simple and the hardware resources are low. In addition, the training process in this method is also very simple, and it is not necessary to collect too many samples in advance, which not only reduces the upfront cost, but also can be based on user habits. The specific command statement of the control item is arbitrarily defined by the user, and thus is suitable for the application of most home appliance remote controllers. The serious shortcoming of DP specific recognition is that its robustness is not ideal. For some people, the speech recognition rate is high, and some people's recognition rate is not high. The recognition rate is higher when training is finished, but the recognition rate is delayed with time. reduce. These shortcomings often cause inconvenience to users. In order to overcome these shortcomings, the improvement of the traditional method has resulted in a significant improvement in recognition performance and robustness, and satisfactory results have been obtained. 1.1 An important factor in the endpoint detection method affecting the performance of isolated word recognition is the accuracy of endpoint detection [4]. In the 10 English-language recognition tests, the 60-millisecond endpoint error reduced the recognition rate by 3%. For speech recognition chip systems for consumer applications, the various interference factors are more complex, making it more difficult to accurately detect endpoint problems. To this end, a two-level endpoint detection scheme called FRED (Frame-based Readl_time Endpoint Detection) algorithm [3] is proposed to improve the accuracy of endpoint detection. The first stage performs a simple real-time endpoint detection on the input speech signal according to the change of its energy and zero-crossing rate, so as to remove the mute to obtain the time domain range of the input speech, and perform spectral feature extraction on this basis. The second stage calculates the energy distribution characteristics of the high frequency, the intermediate frequency and the low frequency band according to the FFT analysis result of the input speech spectrum, and is used to discriminate the light consonant, the voiced consonant and the vowel; after determining the vowel and voiced segments, Expand the search for frames containing speech endpoints to the front and rear ends. The FRED endpoint detection algorithm performs endpoint detection based on the essential features of speech, which can better adapt to environmental interference and changes, and improve the accuracy of endpoint detection. In the specific person identification, the performance of the commonly used FED (Fast Endpoint Detection) [5] and FRED endpoint detection algorithms is compared. Both algorithm tests use the same database, including 7 people's recordings, each speaking 100 names, and each person reading 3 times. The DP template training and recognition algorithm in the test is the traditional fixed-end dynamic time warping (DTW) template matching algorithm [4]. The recognition rate test results of the two endpoint detection algorithms are listed in Table 1. Table 1 Comparison of FED and FRED endpoint detection algorithms for DTW template matching recognition rate Endpoint detection algorithm 1st person 2nd person 3rd person 4th person 5th person 6th person 7th person average FED 92.5% 87% 92.6% 95.6 % 96.2% 96.8% 100% 94.4% FRED 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4% Test results: Using the FRED endpoint detection algorithm, the recognition rate of all speakers has been improved to varying degrees. Therefore, the system uses this two-level endpoint detection scheme. 1.2 Analog matching algorithm DTW is a typical DP-specific human algorithm. In order to overcome the difference of natural speech rate, the dynamic time warping method is used to match the template feature sequence and the speech feature sequence, and the distortion between the two is compared to obtain the recognition decision. in accordance with. It is assumed that a stored word template includes an M-frame cepstrum feature R={r(m); m=1, 2, ∧, M}; the identification feature sequence includes an N-frame cepstral feature T={t(n); =1, 2, ∧, N}. Defining the frame local distortion D(i,j) between r(i) and t(i), D(i,j)=|r(i)-t(i)| 2, through the dynamic programming process, searching Find the path with the smallest cumulative distortion in the path, which is the optimal matching result. Use symmetrical form DTW:
1 Speech Recognition Algorithm At present, speech recognition in consumer electronic products is often implemented by a single-chip computer (MCU) or DSP as an inflammatory hardware platform. This kind of speech recognition is mainly isolated word recognition. It has two implementation schemes: one is based on the hidden Markov statistical model (HMM) framework for non-specific person recognition; the other is based on the dynamic programming (DP) principle. Specific person identification. They have advantages and disadvantages in their applications. The advantage of HMM non-specific personnel is that the user can be used directly without training; and has good stability (that is, the speech recognition performance does not decrease with time for the user). However, non-specific speech recognition also has its drawbacks that are difficult to overcome. First of all, using this method requires a large amount of corpus to be collected in advance in order to train the corresponding recognition model, which greatly increases the upfront cost of applying this technology. Secondly, non-specific person speech recognition is difficult to solve the problem of different dialects in Chinese, limiting Its use area; another factor should also be considered, the specific command words used for control in home appliances should not be completely fixed, and should be changed according to the user's habits, which is hardly recognized by non-specific people. Possible to achieve. Therefore, most home appliance remote controls are not suitable for this solution. The advantage of DP specific person identification is that the method is simple and the hardware resources are low. In addition, the training process in this method is also very simple, and it is not necessary to collect too many samples in advance, which not only reduces the upfront cost, but also can be based on user habits. The specific command statement of the control item is arbitrarily defined by the user, and thus is suitable for the application of most home appliance remote controllers. The serious shortcoming of DP specific recognition is that its robustness is not ideal. For some people, the speech recognition rate is high, and some people's recognition rate is not high. The recognition rate is higher when training is finished, but the recognition rate is delayed with time. reduce. These shortcomings often cause inconvenience to users. In order to overcome these shortcomings, the improvement of the traditional method has resulted in a significant improvement in recognition performance and robustness, and satisfactory results have been obtained. 1.1 An important factor in the endpoint detection method affecting the performance of isolated word recognition is the accuracy of endpoint detection [4]. In the 10 English-language recognition tests, the 60-millisecond endpoint error reduced the recognition rate by 3%. For speech recognition chip systems for consumer applications, the various interference factors are more complex, making it more difficult to accurately detect endpoint problems. To this end, a two-level endpoint detection scheme called FRED (Frame-based Readl_time Endpoint Detection) algorithm [3] is proposed to improve the accuracy of endpoint detection. The first stage performs a simple real-time endpoint detection on the input speech signal according to the change of its energy and zero-crossing rate, so as to remove the mute to obtain the time domain range of the input speech, and perform spectral feature extraction on this basis. The second stage calculates the energy distribution characteristics of the high frequency, the intermediate frequency and the low frequency band according to the FFT analysis result of the input speech spectrum, and is used to discriminate the light consonant, the voiced consonant and the vowel; after determining the vowel and voiced segments, Expand the search for frames containing speech endpoints to the front and rear ends. The FRED endpoint detection algorithm performs endpoint detection based on the essential features of speech, which can better adapt to environmental interference and changes, and improve the accuracy of endpoint detection. In the specific person identification, the performance of the commonly used FED (Fast Endpoint Detection) [5] and FRED endpoint detection algorithms is compared. Both algorithm tests use the same database, including 7 people's recordings, each speaking 100 names, and each person reading 3 times. The DP template training and recognition algorithm in the test is the traditional fixed-end dynamic time warping (DTW) template matching algorithm [4]. The recognition rate test results of the two endpoint detection algorithms are listed in Table 1. Table 1 Comparison of FED and FRED endpoint detection algorithms for DTW template matching recognition rate Endpoint detection algorithm 1st person 2nd person 3rd person 4th person 5th person 6th person 7th person average FED 92.5% 87% 92.6% 95.6 % 96.2% 96.8% 100% 94.4% FRED 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4% Test results: Using the FRED endpoint detection algorithm, the recognition rate of all speakers has been improved to varying degrees. Therefore, the system uses this two-level endpoint detection scheme. 1.2 Analog matching algorithm DTW is a typical DP-specific human algorithm. In order to overcome the difference of natural speech rate, the dynamic time warping method is used to match the template feature sequence and the speech feature sequence, and the distortion between the two is compared to obtain the recognition decision. in accordance with. It is assumed that a stored word template includes an M-frame cepstrum feature R={r(m); m=1, 2, ∧, M}; the identification feature sequence includes an N-frame cepstral feature T={t(n); =1, 2, ∧, N}. Defining the frame local distortion D(i,j) between r(i) and t(i), D(i,j)=|r(i)-t(i)| 2, through the dynamic programming process, searching Find the path with the smallest cumulative distortion in the path, which is the optimal matching result. Use symmetrical form DTW: 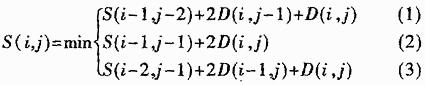 Where S(i,j) is the cumulative distortion and D(i,j) is the local distortion. When the dynamic programming process calculates a fixed node (N, M), the normalized distance of the template dynamic matching can be calculated, and the recognition result is the template entry with the smallest normalized distance: x=argmin{S(N , Mx)}. In order to improve the recognition performance of the DTW recognition algorithm and the robustness of the template, a dual template strategy is proposed, namely x=argmin{S(N,M2x)}. The training entry entered for the first time is stored as the first template, and the same training term entered for the second time is stored as the second template. It is hoped that each entry maintains high recognition performance through two more robust templates. . As with the above test, the performance of the DTW single template and the double template was compared using the 100 personal names of 7 individuals, each with a database of 3 passes. The results are further shown in Table 2. Table 2 Comparison of recognition rates of DTW different template numbers DTW 1st person 2nd person 3rd person 4th person 5th person 6th person 7th person average single template 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4 % Double template 99.4% 96.6% 98.5% 100% 100% 98.8% 100% 99.0% Test results show that by storing two templates, the performance of DTW recognition is greatly improved, and its robustness is greatly improved. Therefore, for a specific person identification system, the use of DTW dual templates is a simple and effective strategy. In summary, the embedded speech recognition chip system adopts the FRED algorithm for improving the endpoint detection performance, and the 12-order Mel frequency cepstrum parameter (MFCC) is used as the feature parameter, and the dual template training recognition strategy is used. Through a series of tests, it is proved that the system has a good recognition performance for the identification of specific people, and can fully meet the requirements of voice control applications in household appliances. 2 Voice Control Remote Control Design At present, the home remote control is mainly button type, and there are two types: one is a fixed pattern, and each key corresponds to one or several patterns, which are preset by the manufacturer. The user can't change it; the other is learning type, which has the function of self-learning remote control code. The user can define the pattern corresponding to each key of the remote control. It can combine multiple remote controllers and use a remote control. Control multiple appliances, and can also be used as a backup of the original remote control. Due to the increasing function of modern home appliances, the above two kinds of remote controllers have too many buttons, and it is difficult for the user to remember the meaning of each button. The speech recognition technology is applied to the learning type remote controller, and the voice command is used instead of the user's memory and use of the command, and a large number of buttons are omitted, and the volume of the remote controller is reduced.
Where S(i,j) is the cumulative distortion and D(i,j) is the local distortion. When the dynamic programming process calculates a fixed node (N, M), the normalized distance of the template dynamic matching can be calculated, and the recognition result is the template entry with the smallest normalized distance: x=argmin{S(N , Mx)}. In order to improve the recognition performance of the DTW recognition algorithm and the robustness of the template, a dual template strategy is proposed, namely x=argmin{S(N,M2x)}. The training entry entered for the first time is stored as the first template, and the same training term entered for the second time is stored as the second template. It is hoped that each entry maintains high recognition performance through two more robust templates. . As with the above test, the performance of the DTW single template and the double template was compared using the 100 personal names of 7 individuals, each with a database of 3 passes. The results are further shown in Table 2. Table 2 Comparison of recognition rates of DTW different template numbers DTW 1st person 2nd person 3rd person 4th person 5th person 6th person 7th person average single template 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4 % Double template 99.4% 96.6% 98.5% 100% 100% 98.8% 100% 99.0% Test results show that by storing two templates, the performance of DTW recognition is greatly improved, and its robustness is greatly improved. Therefore, for a specific person identification system, the use of DTW dual templates is a simple and effective strategy. In summary, the embedded speech recognition chip system adopts the FRED algorithm for improving the endpoint detection performance, and the 12-order Mel frequency cepstrum parameter (MFCC) is used as the feature parameter, and the dual template training recognition strategy is used. Through a series of tests, it is proved that the system has a good recognition performance for the identification of specific people, and can fully meet the requirements of voice control applications in household appliances. 2 Voice Control Remote Control Design At present, the home remote control is mainly button type, and there are two types: one is a fixed pattern, and each key corresponds to one or several patterns, which are preset by the manufacturer. The user can't change it; the other is learning type, which has the function of self-learning remote control code. The user can define the pattern corresponding to each key of the remote control. It can combine multiple remote controllers and use a remote control. Control multiple appliances, and can also be used as a backup of the original remote control. Due to the increasing function of modern home appliances, the above two kinds of remote controllers have too many buttons, and it is difficult for the user to remember the meaning of each button. The speech recognition technology is applied to the learning type remote controller, and the voice command is used instead of the user's memory and use of the command, and a large number of buttons are omitted, and the volume of the remote controller is reduced.  The hardware block diagram of the voice control remote control is shown in Figure 2. It consists of two independent modules: a voice signal processing module and a system control module. The voice signal is calculated by the DSP, flash memory (FLASH), codec (CODEC). DSP is the core of the whole speech recognition module, responsible for speech recognition, speech codec, and FLASH read and write control. The advantages of DSP are fast computing speed, large memory space and fast data exchange speed. It can be used to implement complex algorithms, improve recognition rate, reduce reaction delay, and obtain higher recognition performance. The DSP chip selects AD2186L of Analog Devices, which has the following characteristics: 1 operation speed up to 40MIPS, and all are efficient monotonic cycle instructions; 2 provides 40K bytes of on-chip RAM, of which 8K words (16Bit/word) is data RAM, 8K words (24Bit/word) for program RAM, up to 4 megabytes of memory for storing data or programs; 33.3V operating voltage with multiple power-saving modes. The AD2186L is capable of both algorithms that are related to speech signal calculations and remote controls that use batteries as an energy source. Both FLASH and CODEC also use chips with 3.3V operating voltage. FLASH is AT29LV040A (4M Bit) of American ATMEL Company. It is used as the memory of the system. It is mainly used to store the following contents: parameters required for prompt speech synthesis, codebook data after training for specific people, application and learning of DSP system. Remote control code data. The CODEC selects TLV320AC37 from TI, USA for A/D, D/A conversion, encoding and decoding. The system control module is composed of a single chip microcomputer, an infrared receiving transmitter, and a power management circuit. The microcontroller is responsible for the system control of the entire remote control. The single chip microcomputer is used as the main control chip to perform keyboard scanning. According to the instructions input by the user through the keyboard, the learning remote control code is respectively completed; the DSP is controlled to perform voice training, playback, and recognition; the recognition result is converted into a corresponding remote control code, and is transmitted through the infrared light emitting tube. . The standard RS232 serial protocol communication between the microcontroller and the DSP.
The hardware block diagram of the voice control remote control is shown in Figure 2. It consists of two independent modules: a voice signal processing module and a system control module. The voice signal is calculated by the DSP, flash memory (FLASH), codec (CODEC). DSP is the core of the whole speech recognition module, responsible for speech recognition, speech codec, and FLASH read and write control. The advantages of DSP are fast computing speed, large memory space and fast data exchange speed. It can be used to implement complex algorithms, improve recognition rate, reduce reaction delay, and obtain higher recognition performance. The DSP chip selects AD2186L of Analog Devices, which has the following characteristics: 1 operation speed up to 40MIPS, and all are efficient monotonic cycle instructions; 2 provides 40K bytes of on-chip RAM, of which 8K words (16Bit/word) is data RAM, 8K words (24Bit/word) for program RAM, up to 4 megabytes of memory for storing data or programs; 33.3V operating voltage with multiple power-saving modes. The AD2186L is capable of both algorithms that are related to speech signal calculations and remote controls that use batteries as an energy source. Both FLASH and CODEC also use chips with 3.3V operating voltage. FLASH is AT29LV040A (4M Bit) of American ATMEL Company. It is used as the memory of the system. It is mainly used to store the following contents: parameters required for prompt speech synthesis, codebook data after training for specific people, application and learning of DSP system. Remote control code data. The CODEC selects TLV320AC37 from TI, USA for A/D, D/A conversion, encoding and decoding. The system control module is composed of a single chip microcomputer, an infrared receiving transmitter, and a power management circuit. The microcontroller is responsible for the system control of the entire remote control. The single chip microcomputer is used as the main control chip to perform keyboard scanning. According to the instructions input by the user through the keyboard, the learning remote control code is respectively completed; the DSP is controlled to perform voice training, playback, and recognition; the recognition result is converted into a corresponding remote control code, and is transmitted through the infrared light emitting tube. . The standard RS232 serial protocol communication between the microcontroller and the DSP.  The control software flow chart of the system is shown in Figure 3. Before using, press the “learning button†to enter the learning state. The user first trains the voice command on the learning remote controller and learns the principle control pattern corresponding to each voice command. Press “Recognition Key†to enter the speech recognition state, wait for the speech processing module to return the result, and if the correct recognition result is returned, the corresponding remote control code will be transmitted. For example, the original TV remote control number key "1" corresponds to the central one, the user's training command is "central one", and the remote control code of the original remote control's numeric key "1" is learned and made with the training command "central" 1 set" corresponds. Therefore, when you use it, you only need to say "central one" to the microphone of the learning remote control, and the TV will switch to the central one. In this way, the user does not need to remember the correspondence between each TV station and the station number, and the user-defined commands are easier to remember than the boring channel numbers. If there is no correct command for 30 seconds, the remote controller enters the sleep state. The MCU controls the power management circuit to switch the DSP and FLASH power. The MCU itself enters the sleep state until the user presses the button to wake up the MCU, and then the MCU control restores the DSP and FLASH power supply. , start working again. This is because the DSP consumes the most power in the entire system. When it is not used for a long time, turning off the voice signal processing module can significantly reduce the power consumption of the entire system. Reliability and cost are the biggest challenges in moving from the lab to the market. The dual-template DTW and the two sets of endpoint detection FRED algorithms can effectively improve the recognition rate and robustness under the condition that the system resources and response delay increase extremely. The technology has been successfully applied to the learning remote control, showing the broad prospects of speech recognition technology in the field of home appliances.
The control software flow chart of the system is shown in Figure 3. Before using, press the “learning button†to enter the learning state. The user first trains the voice command on the learning remote controller and learns the principle control pattern corresponding to each voice command. Press “Recognition Key†to enter the speech recognition state, wait for the speech processing module to return the result, and if the correct recognition result is returned, the corresponding remote control code will be transmitted. For example, the original TV remote control number key "1" corresponds to the central one, the user's training command is "central one", and the remote control code of the original remote control's numeric key "1" is learned and made with the training command "central" 1 set" corresponds. Therefore, when you use it, you only need to say "central one" to the microphone of the learning remote control, and the TV will switch to the central one. In this way, the user does not need to remember the correspondence between each TV station and the station number, and the user-defined commands are easier to remember than the boring channel numbers. If there is no correct command for 30 seconds, the remote controller enters the sleep state. The MCU controls the power management circuit to switch the DSP and FLASH power. The MCU itself enters the sleep state until the user presses the button to wake up the MCU, and then the MCU control restores the DSP and FLASH power supply. , start working again. This is because the DSP consumes the most power in the entire system. When it is not used for a long time, turning off the voice signal processing module can significantly reduce the power consumption of the entire system. Reliability and cost are the biggest challenges in moving from the lab to the market. The dual-template DTW and the two sets of endpoint detection FRED algorithms can effectively improve the recognition rate and robustness under the condition that the system resources and response delay increase extremely. The technology has been successfully applied to the learning remote control, showing the broad prospects of speech recognition technology in the field of home appliances. :
0 times
Window._bd_share_config = { "common": { "bdSnsKey": {}, "bdText": "", "bdMini": "2", "bdMiniList": false, "bdPic": "", "bdStyle": " 0", "bdSize": "24" }, "share": {}, "image": { "viewList": ["qzone", "tsina", "tqq", "renren", "weixin"], "viewText": "Share to:", "viewSize": "16" }, "selectShare": { "bdContainerClass": null, "bdSelectMiniList": ["qzone", "tsina", "tqq", "renren" , "weixin"] } }; with (document) 0[(getElementsByTagName('head')[0] || body).appendChild(createElement('script')).src = 'http://bdimg.share. Baidu.com/static/api/js/share.js?v=89860593.js?cdnversion=' + ~(-new Date() / 36e5)];
Other Office & School Supplies
Acrylic File Organizer,Paper File Organizer,Acrylic Pen Holder,Pen Display Holder
Yuefeng Display Product Co., Ltd. , http://www.mw-acrylicdisplay.com