Editor's note: Since the face-changing tool Deepfake became popular all over the world, people have begun to realize that in addition to scam text messages and phone calls, even videos can now be "scams". In order to cope with the criminal risk brought by the new technology, researchers have been trying to discover the difference between fake videos and real videos. At the beginning of this month, the U.S. Department of Defense officially announced a detection tool developed by New York University. They found Some obvious features of GAN-generated video are discussed.
At that time, the U.S. Department of Defense hailed this technology as the beginning of an arms race for AI. Recently, the developers of this technology were interviewed by the media. Let us combine reports and papers to take a closer look at their methods.

The current flaw of Deepfake is that it cannot find enough images with closed eyes.
As the middle of 2018 approaches, the US general election activities have gradually heated up. In many propaganda, a new form of false information has begun to spread widely on social media. This technique of generating fake videos is called "Deepfake", which can replace the faces in the video with other people's faces while maintaining the harmony of facial muscle movements and matching mouth shapes and voices.
Combined with political propaganda, this means that anyone can "spoof" candidates and make fake videos of their "speech" and "activity".
Because this technology is very novel and the effect is exceptional, ordinary people may not be able to distinguish the difference between real videos and fake videos if they don't look carefully. In order to prevent the hidden social security risks behind it, researchers at New York University have recently found a reliable way to distinguish between real and fake videos. They found that in fake videos, the head movements and pupil colors of the characters are usually very weird. When blinking, its eyeballs will move strangely.
What is deepfake?
Since we want to fight against fake videos, let's start with Deepfake. The following is a "case" of its work:

The left side of the video is the real video, and the right side is the processed product of Deepfake. Its working mechanism is similar to mutual translation between languages. It first uses a machine learning system called deep neural network to check a person's facial movements, then synthesize the target person's face, and let the latter make similar actions.
Before generating realistic videos, this deep neural network requires a large amount of target task image data. The number and diversity of images determine the "learning" effect of the network-the more data, the more realistic the simulation effect.
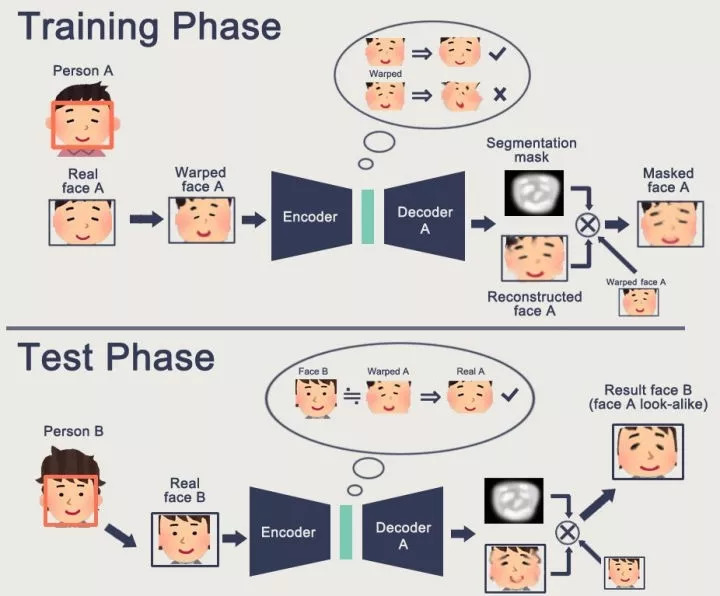
The figure above is a detailed illustration of the neural network training and testing process. After watching the video, some people may have questions: Why is the fake face generated by Deepfake so natural? This is because during the training phase, we will first cut out the face of the target person A, locate the facial features, train a face that distorts A no matter what, and finally generate a normal A face network.
Once the above network is trained, we can input B's face into it. At this time, in the eyes of the neural network, B's face is actually the distorted A's face, so it will directly "correct" it. As for details such as expressions and mouth shapes, they have been learned during the training process. The more data, the better the effect. I believe this is not difficult to understand.
In addition to the above basic content, in order to ensure the generation effect, we also need to pay attention to issues such as clarity, face recognition effects, and image fusion.
Blink/not blink?
If we look at the above video again, I believe that many attentive readers will find that in the fake video, the characters tend to have "no gods in their eyes" and hardly blink their eyes. This is a weakness of Deepfake at present.
Of course, this weakness does not come from the algorithm itself, but more from the data set it uses. The blink frequency of a healthy adult is 2-10 seconds, and a blink takes one-tenth to four-tenths of a second. In the real speech video, it is quite normal for the presenter to blink, but almost all the dummy in the fake video are "not blinking" masters.

Replace the host’s face with Nicholas Cage (corresponding to the video frame)
This is because when training a deep neural network, we use static images from the network. Even for public figures like Nicholas Cage, most of his photos are with eyes open, and unless for some artistic effect, photographers will not publish photos of stars with eyes closed. This means that the images in the data set cannot represent the natural movement of the eyeballs.
Since there are almost no blinking images in the data set, the probability of Deepfake learning to "blink" is almost zero. But when you see this, some people may have doubts. In the previous video, the blinking lens also appeared. Is this basis unreliable? This is related to the frequency and speed of human blinking.
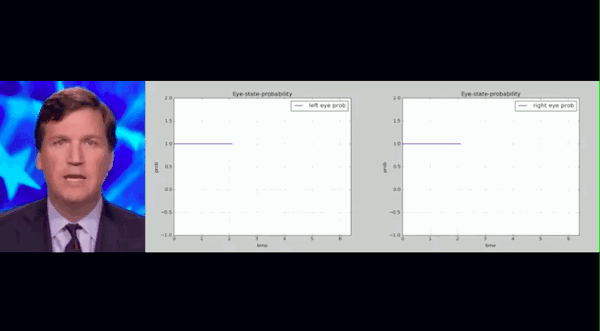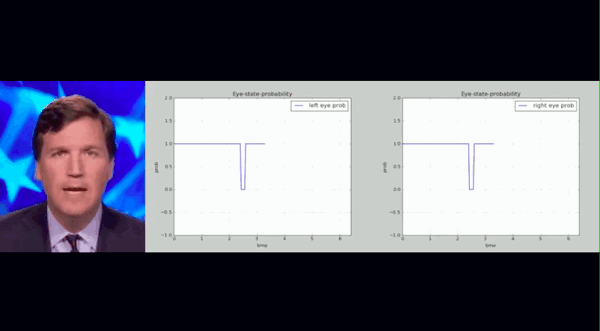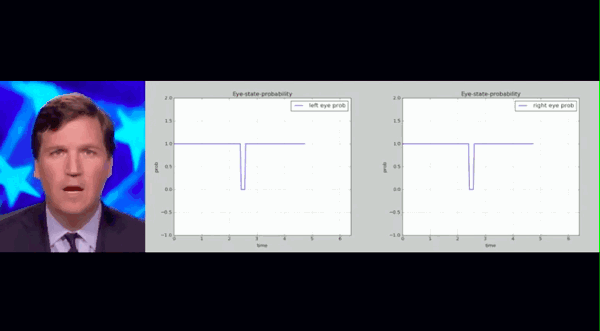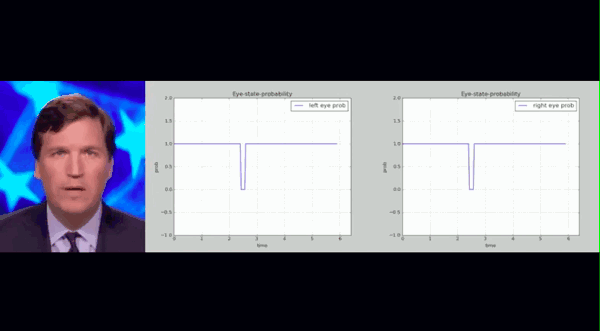
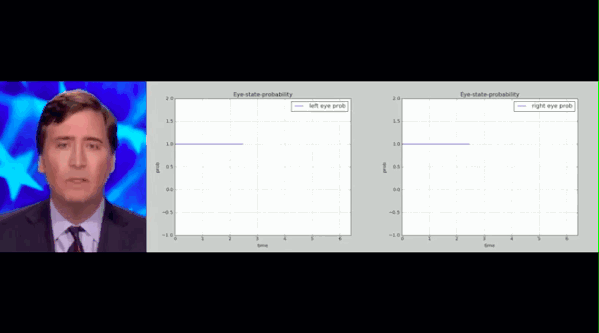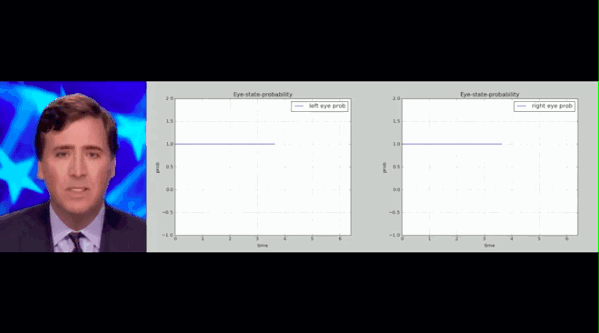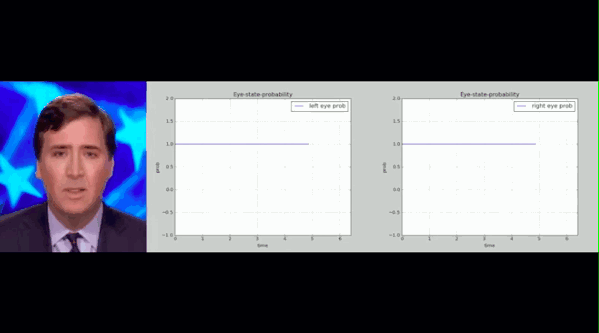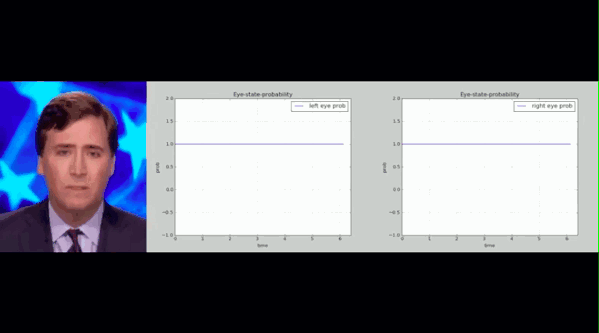
The above is the blinking records of people in real and fake videos. The researchers counted the blink frequency of real people in all videos and framed a range. They found that the blink frequency of fake people in Deepfake videos was much lower than this range.
How to detect blinking?
With the above findings, the entire "counterfeiting" problem can be reduced to the "blink detection" problem.
The author of the paper has developed a method to detect when a person blinks in a video. More specifically, they introduced two neural networks. The first network scans each frame of the video to detect whether it contains a human face, and if there is a human face, it automatically locates the eye. After that, the first network inputs the screenshots of the eyes into the second network, which uses the appearance, geometric characteristics and movement of the eyes to determine whether the eyes are open or closed.
The following is a schematic diagram of the second deep neural network LRCN:
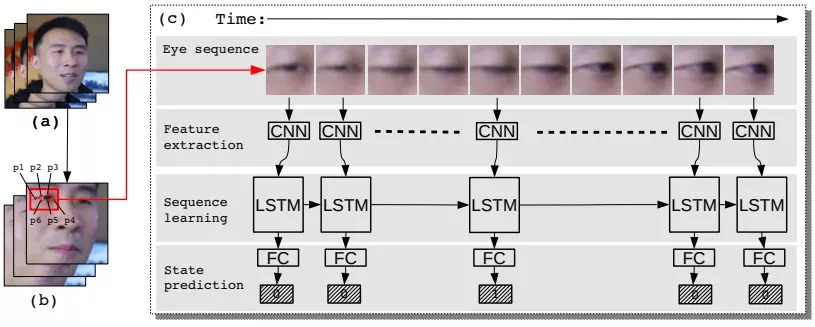
It contains three modules: feature extraction, sequence learning and state prediction.
Among them, the feature extraction module (second line) is responsible for converting the input eye image into features that the neural network can "understand". This is a CNN based on the VGG16 architecture. The sequence learning module (third row) is composed of RNN and LSTM. The use of LSTM-RNN is to increase the amount of information storage of the model and avoid the disappearance of gradients when using the back propagation over time (BPTT) algorithm. The last module-state prediction, is composed of a fully connected layer, which inputs the output of LSTM, and uses a probability to predict whether the eye is open (0) or closed (1).
According to the experimental results, the accuracy of LRCN is as high as 95%.
Of course, although the thesis only introduces the method of judging the blink frequency, it ends here. But according to Siwei Lyu's previous introduction, their team actually found a more efficient technology, just to prevent some people from maliciously iterating Deepfake, this method needs to be kept secret for the time being.
Defects of the thesis method
In an interview with the media, Siwei Lyu himself admitted that the paper only proposed a short-term effective method, its "lifetime" may be very short, and the method to crack it is also very simple.
As we mentioned before, algorithms can't blink, mainly because there is no blink data. In other words, if we can provide a large number of images of different blinking stages, it is only a matter of time before the deep neural network learns to blink. What's more, in order for Nicholas Cage to learn to blink, we don't need to send paparazzi to sneak photos, it is enough to collect our own eye data.
In addition, for the above type of video, this method does not work. Because it is different from Deepfake's full face transplantation, it moves fake mouths and fake voices (synthetic voices can also be faked in these years) to real people's faces.
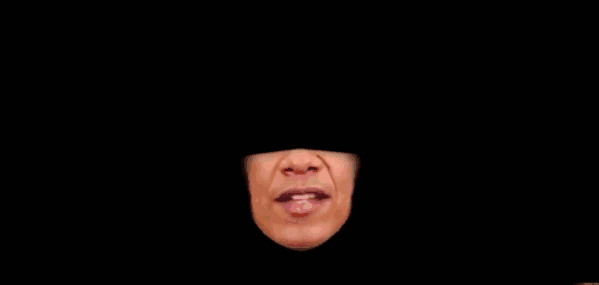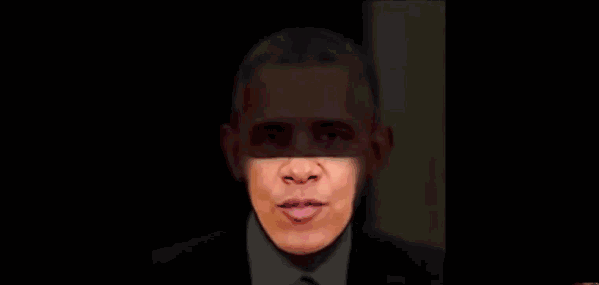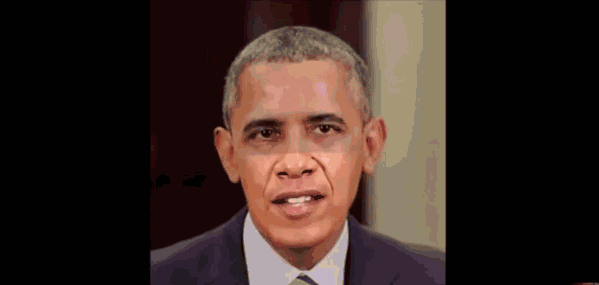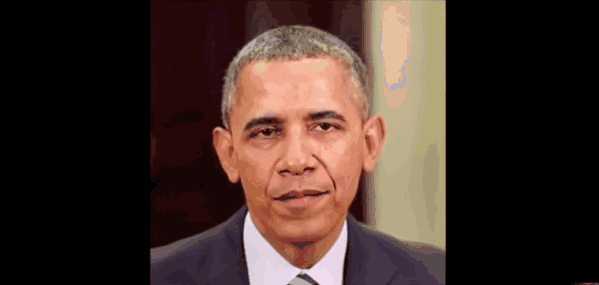
This is a result published by a research team at the University of Washington last year. It does not need to scan a large amount of speech audiovisual materials, nor does it need to analyze the mouth shapes of different people uttering the same sentence. It only needs audiovisual materials, and the cost and scale are smaller. , The production time is shorter (17 hours).
Therefore, there is still a long way to go to "crack counterfeiting" for the whole people, and this method is only the first step currently taken. In the future, generating fake videos and detecting fake videos will become common games in daily life, but this should not be what everyone wants to see. While encouraging researchers to develop more reliable detection methods, we should call for an end to the abuse of technology.
In addition to stop making some vulgar and illegal videos, the film industry should also use it for the right way, and don't let technology become a new "shortcut" for cutting out traffic stars.
Shenzhen Ever-smart Sensor Technology Co., LTD , https://www.fluhandy.com