At present, three types of methods are generally used to improve the recognition performance of characters: the first category is to find a better classification recognition algorithm; the second category is to combine several classifiers and complement each other, according to the characteristics of different aspects, such as literature The third category is to extract features with stronger description capabilities, combined with other auxiliary features for classification, such as literature.
This paper uses the support vector machine (SVM) method to solve the license plate character recognition problem, which belongs to the first class method. SVM can automatically find support vectors that have better distinguishing ability for classification. The resulting classifier can maximize the inter-class spacing and achieve the purpose of correctly distinguishing categories; it can be used to solve finite sample, nonlinear and high-dimensional pattern recognition problems. Out of a number of unique superior performance, and has the characteristics of strong adaptability and high efficiency.
2 Support Vector Machine Introduction Support Vector Machine (SVM) is a classification technology proposed by Vapnik and its research group for the classification problem of two categories. It is a new and promising classification technology. The basic idea of ​​SVM is to construct the optimal hyperplane in the sample space or feature space to maximize the distance between the hyperplane and different sample sets, so as to achieve the maximum generalization ability. The detailed description of the algorithm can be found in the literature. .
According to Vapnik's structural risk minimization principle, the support vector machine method maximizes the generalization ability of the learning machine, so that the decision rules obtained by a limited number of training samples can still obtain small errors for independent test sets. In this way, only a limited number of samples are involved in the training, and the classifier generated by the training can be guaranteed to have a small error. When the license plate character is recognized, only a limited number of samples can participate in the training relative to the predicted samples. The support vector machine method can make the classifier generated by the training only have small errors in identifying the license plate characters, and greatly reduce the training time. .
For data classification problems, the mechanism of the general neural network method can be simply described as: the system randomly generates a hyperplane and moves it until the points in the training set belonging to different categories are located on different sides of the plane. This processing mechanism determines that the segmentation plane finally obtained by the neural network method is not an optimal hyperplane, but a local suboptimal hyperplane. SVM transforms the optimal hyperplane solution problem into a quadratic function optimization problem under inequality constraints. This is a convex quadratic optimization problem. There is a unique solution, which can guarantee that the found extreme solution is the global optimal solution.
The SVM maps the input data to a feature space with high or even infinite dimensions through a nonlinear function, and linearly classifies the high-dimensional feature space to construct the optimal classification hyperplane, but solves the optimization problem and calculates the discriminant function. It is not necessary to explicitly calculate the nonlinear function, but only the kernel function, so as to avoid the feature space dimension disaster problem.
Each sample in the license plate character recognition problem is a character image, and each character image is composed of many pixels and has a high dimensional characteristic. Through the calculation of the kernel function, the SVM avoids the network structure design problem caused by the neural network to solve the high-dimensional problem of the sample space, so that the training model has nothing to do with the dimension of the input data; and the whole image of each character is input as a sample. Feature extraction is not required, saving recognition time.
This article refers to the address: http://
3 The construction of the license plate character classifier The standard license plate format in China is: X1X2. X3X4X5X6X7, where X1 is the abbreviation of each province, municipality and autonomous region, X2 is the English alphabet, X3X4 is the English alphabet or Arabic numeral, X5X6X7 is the Arabic numeral, and for different Xl, the value range of X2 is different. There is a small dot between X2 and X3.
For the arrangement characteristics of license plate characters, in order to improve the overall recognition rate of the license plate, four classifiers can be designed to identify the license plate characters, namely Chinese character classifier, digital classifier, English alphabet classifier, digital + letter classifier. According to the serial number of the characters in the license plate, the corresponding classifier is selected for recognition, and then the recognition result is combined according to the character serial number, and the recognition result of the entire license plate is obtained. The four classifiers are shown in Figure 1.
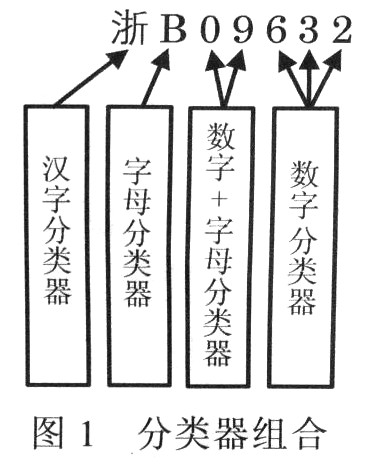
There are more than 50 Chinese characters in the character set, 31 of which are short names of provinces, municipalities and autonomous regions; English letters are all uppercase letters, without the letter "I", and the letter "o" is classified as the number "0", so the English alphabet set consists of 24 uppercase letters; numbers are 0-9 Arabic numerals.
Support vector machine is proposed for the classification of two categories, but license plate character recognition is a multi-category classification problem. It is necessary to extend the two-category classification method to multi-category classification. This paper adopts one-to-one classification method. One-against-one method is to select two different categories to form an SVM sub-classifier, so that for k-type problems, there are k(k-1)/2 SVM sub-classifiers. When constructing the SVM sub-classifiers of category i and category j, sample data belonging to category i and category j is selected as training sample data in the sample data set, and data belonging to category i is marked as positive, and data belonging to category j is to be Mark as negative. During the test, the test data is tested separately for k(k-1)/2 SVM sub-classifiers, and the scores of each category are accumulated, and the category corresponding to the highest score is selected as the category of test data.
4 Selection of the best parameter model In this paper, after the license plate image and character segmentation of the 768×576 pixel car license plate image collected by an actual bayonet system, each segmented license plate character is binarized, and the character stroke corresponds. The pixel is set to 1, the background pixel is set to 0, and each character is normalized to 13x24 pixels, and the number l~7 is programmed according to the position of each character in the license plate.
The total number of license plate pictures selected in this article is 132, including night, backlight, strong character wear, license plate tilt and other brands next to the license plate; there are 129 pictures to achieve correct positioning of the license plate, the license plate positioning rate is 97.73%; 120 The picture can be correctly segmented for all characters, and the character segmentation rate is 93.02%.
In this paper, each character is taken as a sample, each sample has a dimension of 312 (13x24), and is divided into four types of samples according to its serial number. Each type of sample is divided into two parts, 60% of the samples are trained to produce the model, and another 40% is used for testing. The kernel function uses the radial basis function K(xi,x)=exp(-||x-xi||2/σ2) The four types of classifiers are trained and generated, and the optimal parameter model is selected to form the four best classifiers for the overall recognition of the license plate characters.
In order to solve the optimal classifier parameters (C, σ2), we choose the bilinear method to solve the optimal parameters. The following steps are taken for each classifier model:
The first step: determine the optimal parameter C according to the recognition accuracy rate. First, suppose C=10, take σ2=10-1, 100,101,102,103, get the highest recognition accuracy rate corresponding to σ2, then fix σ2, change the value of C, and get the highest recognition accuracy rate at this time. C value, as the best parameter C.
The highest recognition accuracy of the class 4 classifier corresponds to (C, σ2) of (10, 100), and the optimal C = 10 is determined.
Step 2: Determine the best parameters (C, σ2). Fix the optimal parameter C, take σ2=l,10,100,200,300,400,500,600,700,800,900,1000, take the (C, σ2) corresponding to the highest recognition accuracy rate as the classifier model. The best parameters.
It is found that when the value of σ2 becomes less than 100, the corresponding recognition accuracy rate is gradually reduced; when the value of σ2 becomes 100 or more, the corresponding recognition correctness rate first increases and then decreases, and “Appearsâ€. Peak value, taking the model parameter corresponding to "peak" as the best parameter. The four best classifiers are shown in Table 1 below.
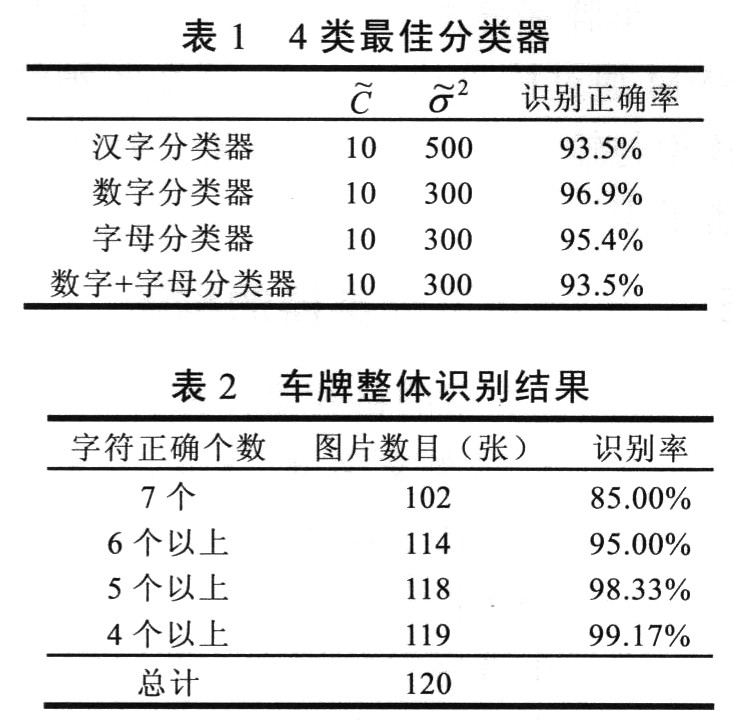
Experimental observation and analysis, the classifier has a certain degree of bias when it is recognized, that is, the number of certain types of samples participating in the training is large, and the probability that the predicted samples are recognized as such is large. For example, if there are more "Zhe" characters in the training sample, the Chinese character classifier will It is more likely that the predicted sample will be identified as “Zhejiangâ€, but in fact, the number of “Zhe†characters in the sample is predicted to be large, which invisibly improves the recognition accuracy.
5 Experiments and results In this paper, the license classifiers of the above four types of best classifiers are used to identify all the license plate characters as a whole. The recognition results are shown in Table 2.
In practical application, the correct number of license plate characters can meet the requirements. The license plate character recognition results in this paper and related literature are shown in Table 3.
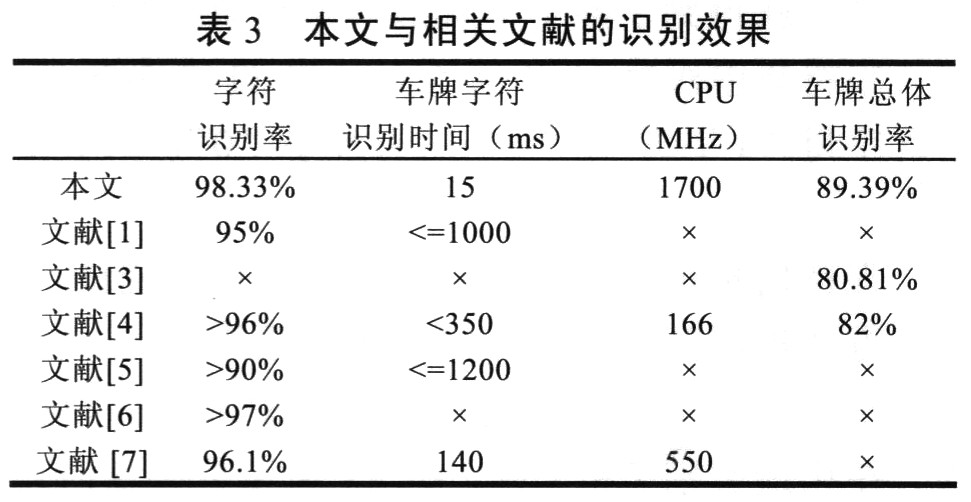
Observation and analysis found that the main reason affecting the recognition effect is the misunderstanding of similar characters, such as the characters "D" and "0", "B" and "8", etc.; there are many strokes in Chinese characters, and the binarization operation is easy to cause the strokes to be blurred. To misunderstand Chinese characters.
6 Conclusions In this paper, the SVM method is introduced into the license plate character recognition. Based on the detailed analysis of the arrangement characteristics of the license plate characters, four different categories of SVM character classifiers are constructed. According to the serial number of the license plate characters, the corresponding identification will be carried out. By identifying the combination of results, the number of the entire license plate is obtained.
The SVM method solves the high-dimensional sample identification problem by using the kernel function. It does not need to design the model network structure, and does not need feature extraction. Only limited sample participation training is needed, which saves the recognition time, which is very consistent with the requirements of license plate character recognition. . This paper uses the one-to-one method to extend the SVM method from two-category recognition to multi-category recognition, and achieves satisfactory recognition results. However, the one-to-one distinction method needs to ensure the adequacy of training samples, and all categories of samples are required to participate in training.
The test results show that the method has good practicability, and further reducing the similar characters and Chinese characters misunderstanding is the direction of the work after this work. The key is to strengthen the image preprocessing, improve the character segmentation method and the binarization method. Character strokes are clearer.
Draw-wire sensors of the wire sensor series measure with high linearity across the entire measuring range and are used for distance and position measurements of 100mm up to 20,000mm. Draw-wire sensors from LANDER are ideal for integration and subsequent assembly in serial OEM applications, e.g., in medical devices, lifts, conveyors and automotive engineering.
Linear Encoder,Digital Linear Encoder,Draw Wire Sensor,1500Mm Linear Encoder
Jilin Lander Intelligent Technology Co., Ltd , https://www.jllandertech.com