Machine learning originated from artificial intelligence and can give computers the ability not to be realized by traditional programming, such as aircraft autopilot, face recognition, computer vision and data mining.
There are many algorithms for machine learning. Many times people are confused. Many algorithms are a type of algorithm, and some algorithms are extended from other algorithms. Here, we introduce you from two aspects, the first aspect is the way of learning, and the second aspect is the similarity of the algorithm.
learning methodSorting the algorithm according to the learning method allows people to consider the most appropriate algorithm based on the input data to obtain the best results when modeling and algorithm selection.
Supervised learning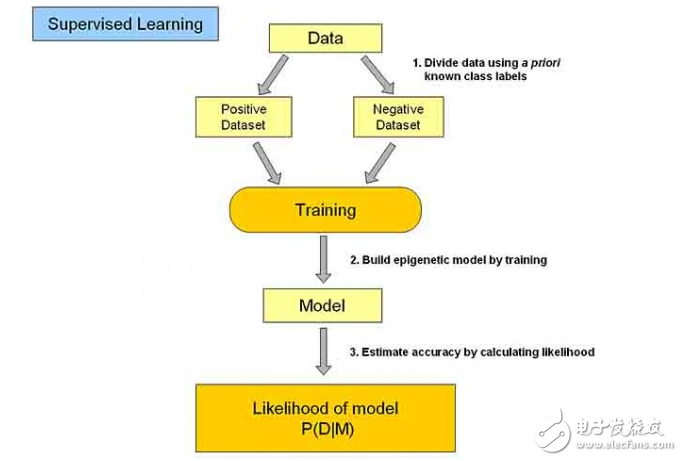
In supervised learning, the input data is called “training data†and each set of training data has a clear class label. When establishing a predictive model, supervised learning establishes a learning process, compares the predicted results with the actual results of the “training dataâ€, and continuously adjusts the predictive model until the predicted outcome of the model reaches an expected accuracy.
Common application scenarios for supervised learning such as classification and regression. Common algorithms are Linear Regression, LogisTIc Regression, Neural Network, SVMs.
Unsupervised learning
In unsupervised learning, the data is not specifically identified, and the learning model is used to infer some of the inherent structure of the data.
Common application scenarios include learning of association rules and clustering. Common algorithms include K-means Clustering, Principal Component Analysis, and Anomaly DetecTIon.
Semi-supervised learning
In this learning mode, the input data portion is identified and the portion is not identified. This learning model can be used to make predictions, but the model first needs to learn the internal structure of the data in order to reasonably organize the data for prediction. The application scenario includes classification and regression. The algorithm includes some extensions to the commonly used supervised learning algorithms. These algorithms first attempt to model the unidentified data, and then predict the identified data. Graph Inference or Laplacian SVM.
Reinforcement learning
In Reinforcement Learning, input data is used as feedback to the model. Unlike the supervisory model, input data is just a way to check the model right or wrong. In reinforcement learning, the input data is fed back directly to the model, which must be adjusted immediately. Common application scenarios include dynamic systems and robot control. Common algorithms include Q-Learning and Temporal difference learning.
In the context of enterprise data applications, the most commonly used models are the models of supervised learning and unsupervised learning. In the field of image recognition, semi-supervised learning is a hot topic due to the large amount of non-identified data and a small amount of identifiable data. More applications for reinforcement learning are in robot control and other areas where system control is required.
Algorithm similarity regression algorithm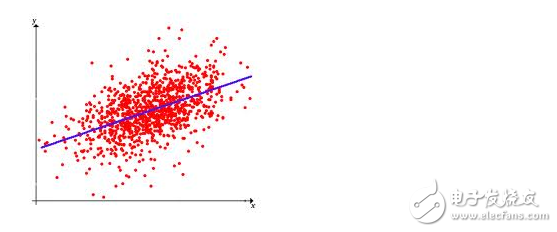
Regression algorithms are a type of algorithm that attempts to explore the relationship between variables using a measure of error. The regression algorithm is a tool for statistical machine learning. In the field of machine learning, people talk about regression, sometimes referring to a type of problem, sometimes referring to a type of algorithm, which often confuses beginners. Common regression algorithms include: Ordinary Least Square, LogisTIc Regression, Stepwise Regression, MulTIvariate Adaptive Regression Splines, and Local Scattering Smooth Estimation (Locally Estimated Scatterplot Smoothing).
Kernel-based algorithm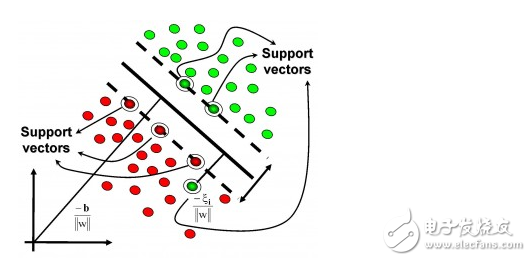
The most famous of the kernel-based algorithms is the support vector machine (SVM). Kernel-based algorithms map input data to a high-order vector space in which some classification or regression problems can be solved more easily. Common kernel-based algorithms include: Support Vector Machine (SVM), Radial Basis Function (RBF), and Linear Discriminate Analysis (LDA).
Clustering Algorithm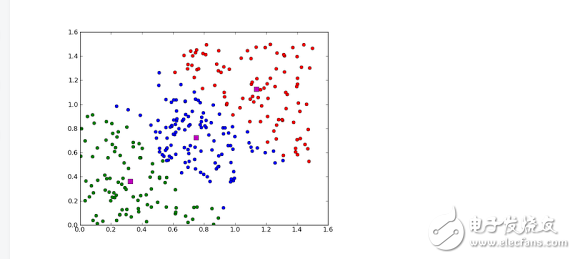
Clustering, like regression, sometimes describes a type of problem, sometimes describing a type of algorithm. Clustering algorithms typically merge input data in a central or hierarchical manner. So the clustering algorithm tries to find the intrinsic structure of the data in order to classify the data according to the greatest commonality. Common clustering algorithms include the k-Means algorithm and Expectation Maximization (EM).
Dimensionality reduction algorithm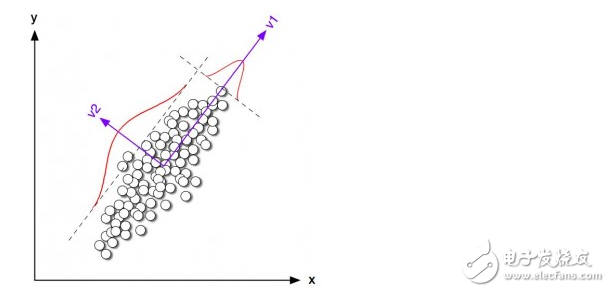
Like the clustering algorithm, the reduced dimension algorithm attempts to analyze the intrinsic structure of the data, but the reduced dimension algorithm attempts to summarize or interpret the data with less information in an unsupervised learning manner. Such algorithms can be used to visualize high-dimensional data or to simplify data for supervised learning. Common algorithms include: Principal Component Analysis (PCA), Partial Least Square Regression (PLS).
Integrated learning algorithm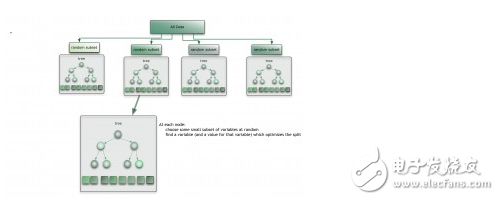
The integration algorithm independently trains the same samples with some relatively weak learning models and then integrates the results for overall prediction. The main difficulty of the integrated algorithm is how to integrate independent weak learning models and how to integrate the learning results. This is a very powerful algorithm and it is also very popular. Common algorithms include: Boosting, Bootstrapped Aggregation (Bagging), AdaBoost, Random Forest, etc. (This type of algorithm is used in the competition, the effect is better)
Instance-based algorithm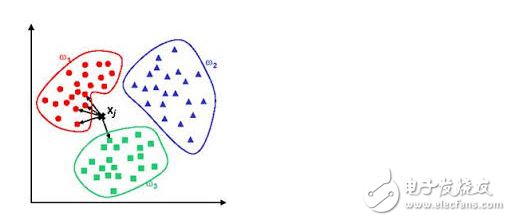
Instance-based algorithms are often used to model decision problems. Such models often select a batch of sample data and then compare the new data to the sample data based on some approximation. In this way, find the best match. Therefore, instance-based algorithms are often referred to as "winner-take-all" learning or "memory-based learning." Common algorithms include k-Nearest Neighbor (KNN), Learning Vector Quantization (LVQ), and Self-Organizing Map (SOM).
Decision tree learning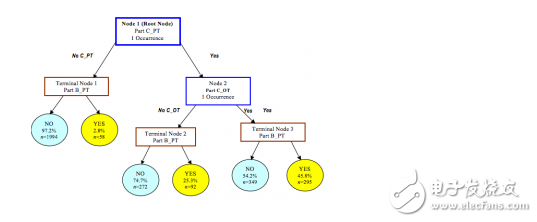
The decision tree algorithm uses a tree structure to establish a decision model based on the attributes of the data. Decision tree models are often used to solve classification and regression problems. Common algorithms include: Classification and Regression Tree (CART), ID3 (Iterative Dichotomiser 3), C4.5, Random Forest (Random Forest), etc.
Bayesian method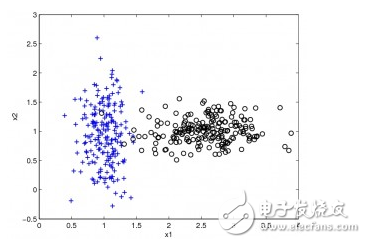
Bayesian method is a kind of algorithm based on Bayes' theorem, which is mainly used to solve classification and regression problems. Common algorithms include the Naive Bayes algorithm and the Bayesian Belief Network (BBN).
Artificial neural networksArtificial neural network algorithm simulates biological neural network and is a kind of pattern matching algorithm. Usually used to solve classification and regression problems. It is a huge branch of machine learning. Important artificial neural network algorithms include: Perceptron Neural Network, Back Propagation, Hopfield Network, and Self-Organizing Map (SOM). (Now deep learning is developed from artificial neural networks)
Deep learningCommon deep learning algorithms include: Restricted Boltzmann Machine (RBN), Deep Belief Networks (DBN), Convolutional Network, and Stacked Auto-encoders. (To date, the most successful are CNN and LSTM.)
Water-cooled capacitor is supercapacitor is a capacitor with a capacity of thousands of farads.According to the principle of capacitor, capacitance depends on the distance between the electrode and electrode surface area, in order to get such a large capacitance, as far as possible to narrow the distance between the super capacitor electrode, electrode surface area increased, therefore, through the theory of electric double layer and porous activated carbon electrode.
Water-Cooled Capacitor,Water-Cooled Power Capacitor,Water-Cooled Electric Heat Capacitor,Water-Cooled Electric Heating Capacitor
YANGZHOU POSITIONING TECH CO., LTD. , https://www.cnpositioning.com